The Quietest Threat to Your Study’s Validity: A Mislabeled Cage
Posted on June 22, 2026
We talk about the reproducibility crisis in terms of statistics and study design. Some of it starts somewhere much smaller — a faded digit on a cage card.
If you’ve spent any time in a vivarium, you’ve squinted at a cage card. A digit half-worn away by a gloved thumb. A “3” that could just as easily be an “8.” A card that hit the floor during a cage change and went back one slot over. It feels like a two-second fix, and most of the time it is. The problem is the one time it isn’t caught, and nobody notices.
When people talk about the reproducibility crisis, they reach for the big structural explanations: underpowered studies, over-standardization, publication bias, weak statistics. Those are all real. But sitting underneath the methodology is a more boring question that rarely makes it into a paper — did the right data get attached to the right animal? When the answer is no, nothing flags it. The error just rides along with everything downstream.
How one wrong ID becomes a wrong conclusion
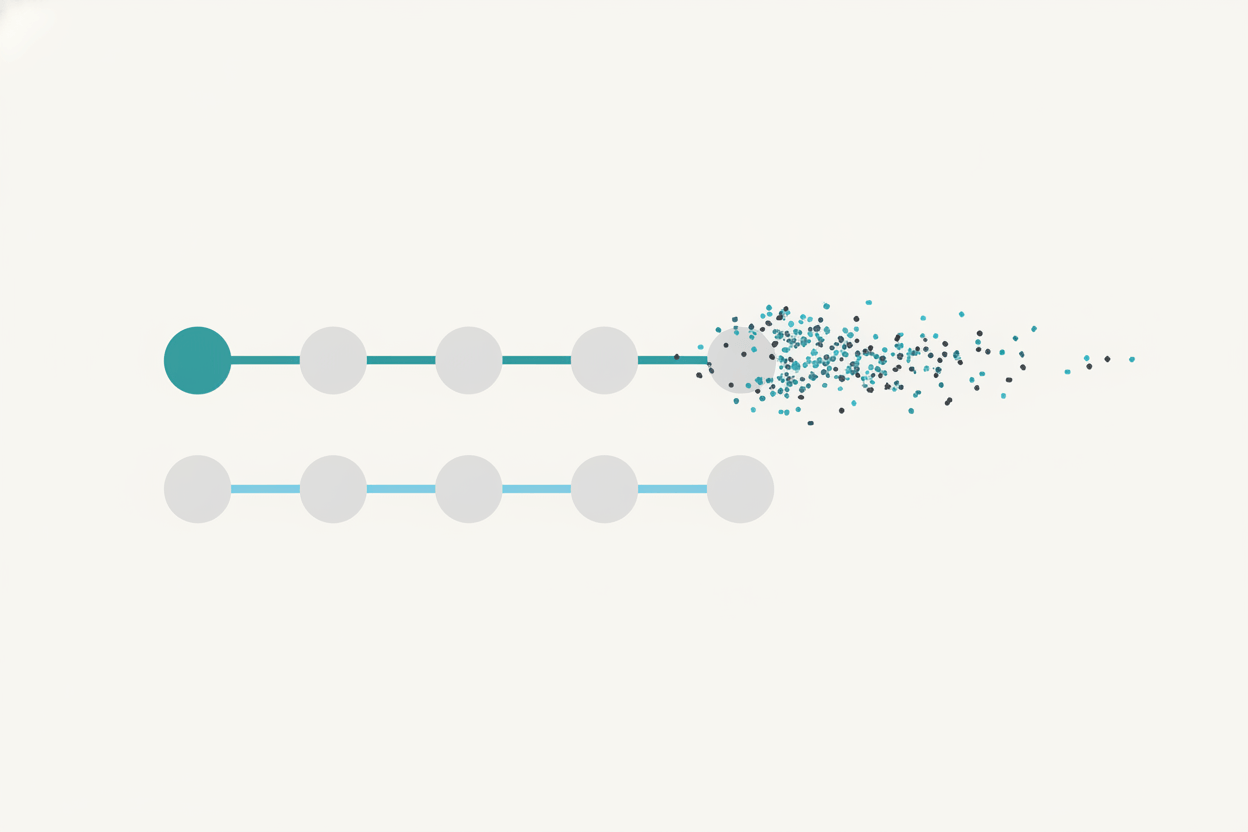
Say an animal gets enrolled under the wrong ID. From that point on, its weights, dosing records, and observations all file against the wrong subject. By the time you’re analyzing, two animals’ data have effectively traded places, or one animal’s results are smeared across two records. None of it looks wrong on screen. The numbers are perfectly plausible. That’s what makes it dangerous: a slip like this doesn’t throw an obvious outlier you’d catch on a plot. It just hands you a dataset that’s quietly off.
Now run that across a study that lasts months, with a few different technicians, shift handoffs, and a fair amount of manual data entry. What you get is a slow trickle of noise from a source no statistical method can clean up after the fact.
You can’t fix at analysis what went wrong at the cage.
The scale of the problem
This isn’t a fringe concern. Preclinical research has a well-documented reproducibility problem — a meaningful share of studies don’t replicate across labs, which chips away at confidence in findings and slows anything useful reaching patients. In a 2016 survey in Nature, more than 70% of researchers said they’d tried and failed to reproduce another scientist’s results, and more than half had failed to reproduce their own. The causes are tangled, but a recurring one is plain human-introduced variability — avoidable, systemic, and not the occasional bad day.
The cost isn’t only scientific. Every result that doesn’t hold up represents animals, technician hours, reagents, and facility time spent producing data nobody can trust. With the whole field under pressure to do more with fewer animals, waste from a preventable error is the hardest kind to defend.
Where identity errors creep in: Handwritten or hand-typed IDs · faded, soiled, or swapped cage cards · ambiguous characters (0/O, 1/I, 3/8) · transcription during data entry · manual matching between the animal, the cage, and the database · handoffs between shifts and personnel.
How the industry closes the gap
If there’s a bright spot, it’s that this is one of the more fixable problems in the lab. Most facilities already run some combination of the following.
Standardized identifiers come first. Once IDs follow a controlled scheme instead of whatever someone writes by hand, a whole class of “is that a 3 or an 8” errors simply can’t happen.
From there, most labs move to machine-readable IDs — barcodes or 2D data-matrix codes — so a scanner makes the match between animal, cage, and record instead of an eye and a pen. The win isn’t speed. It’s that scanning deletes the transcription step, which is where the errors were getting in.
The bigger jump is having that scan write straight into the study software or LIMS. Re-keying a number from one system into another is exactly the kind of step that corrupts data quietly, and direct capture takes it off the table. You also get real-time tracking from enrollment onward.
The last piece is the audit trail. A timestamped record of who logged what, and when, turns “we’re pretty sure the data are right” into “we can show the data are right.” That distinction matters more every year as regulators look harder.
The unglamorous fundamentals are the leverage
It’s tempting to assume better science is mostly a matter of better study design and smarter methods. Those help. But a real chunk of the problem is far more ordinary — making sure the right data lands on the right animal every time, and taking the manual transcription step out of the loop wherever you can.
Nobody got into this work for the cage cards. Still, the studies that hold up tend to be the ones where the unglamorous fundamentals never got to slip — more often than most of us like to admit.
Where we sit on this. Full disclosure: RapID Lab makes automated identification tools, so this is our corner of the world and we’re not neutral about it. The principle holds regardless of whose products are on the bench, though — reliable IDs, captured cleanly, are just good science. Whatever method gets you there, it’s worth getting right.
References
- The Jackson Laboratory. “Fostering Replicability in Preclinical Research.” JAX Blog, May 2025. jax.org
- Baker, M. “1,500 scientists lift the lid on reproducibility.” Nature 533, 452–454 (2016). nature.com
- Voelkl, B., Vogt, L., Sena, E. S., & Würbel, H. “Reproducibility of preclinical animal research improves with heterogeneity of study samples.” PLOS Biology 16(2): e2003693 (2018). journals.plos.org
About RapID Lab. RapID Lab makes minimally invasive, automated 2D-barcode ear tags for identifying rodents in preclinical research. We’re a small team in San Francisco focused on accurate, low-stress animal identification. rapidlab.com
This article is for general informational purposes and reflects RapID Lab’s perspective on industry practice. It is not a substitute for your facility’s SOPs or regulatory requirements.